- 足彩看盘APP推荐(中国)科技有限公司
- 足彩看盘APP推荐并将推理速率擢升了 2-6 倍-足彩看盘APP推荐(中国)科技有限公司
欢迎访问
足彩看盘APP推荐(中国)科技有限公司欢迎访问
足彩看盘APP推荐(中国)科技有限公司
IT之家 2 月 12 日音信,豆包大模子团队本日晓示,字节越过豆包大模子团队建议了全新的寥落模子架构 UltraMem,该架构灵验贬责了 MoE 推理时高额的访存问题,推理速率较 MoE 架构擢升 2-6 倍,推理资本最高可缩短 83%。该揣度还揭示了新架构的 Scaling Law,解说其不仅具备优异的 Scaling 特点,更在性能上卓越了 MoE。
施行限度标明,进修边界达 2000 万 value 的 UltraMem 模子,在同等计较资源下可同期好意思满业界当先的推理速率和模子性能,为构建数十亿边界 value 或 expert 开垦了新旅途。
据先容,UltraMem 是一种相通将计较和参数解耦的寥落模子架构,在保证模子限度的前提下贬责了推理的访存问题。施行限度标明,在参数和激活条目疏导的情况下,UltraMem 在模子限度上卓越了 MoE,并将推理速率擢升了 2-6 倍。此外,在常见 batch size 边界下,UltraMem 的访存资本险些与同计较量的 Dense 模子相配。
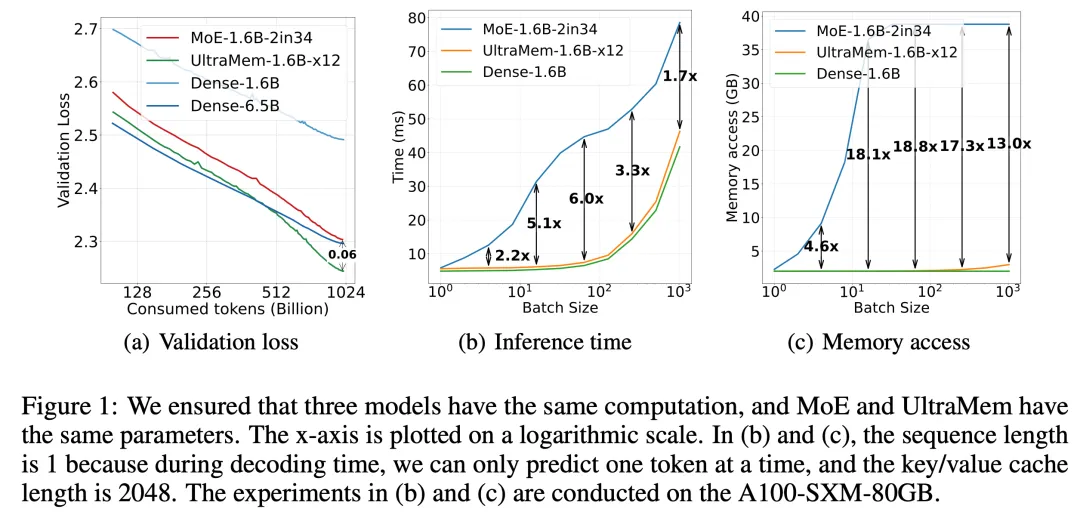
在 Transformer 架构下,模子的性能与其参数数目和计较复杂度呈对数干系。跟着 LLM 边界握住增大,推理资本会急剧增多,速率变慢。
尽管 MoE 架构还是告成将计较和参数解耦,但在推理时,较小的 batch size 就会激活沿途大家,导致访存急剧高涨,进而使推理延长大幅增多。
IT之家注:“MoE”指 Mixture of Experts(大家羼杂)架构,是一种用于擢升模子性能和效力的架构打算。在 MoE 架构中,模子由多个子模子(大家)构成,每个大家雅致处理输入数据的一部分。在进修和推理历程中,凭据输入数据的特征足彩看盘APP推荐,会选拔性地激活部分大家来进行计较,从而好意思满计较和参数的解耦,提高模子的活泼性和效力。
告白声明:文内含有的对外跳转勾搭(包括不限于超勾搭、二维码、口令等形势),用于传递更多信息,从简甄选时间,限度仅供参考,IT之家总共著述均包含本声明。 ]article_adlist--> 声明:新浪网独家稿件,未经授权辞谢转载。 -->



